
About Me
Since August 2024, I am a Research Scientist at Google Zurich in the Semantic Perception team of
Dr. Federico Tombari.
Before, I did my Ph.D. in the Computer Vision Lab at ETH Zurich supervised by
Prof. Luc Van Gool
and Dr. Dengxin Dai.
My Ph.D. was focused on domain-robust and label-efficient visual scene understanding
including domain-adaptive, domain-generalizable, semi-supervised, self-supervised, language-guided, and generative learning for semantic segmentation.
During my Ph.D., I also interned at Google to work on vision-language models for label-efficient semantic segmentation.
I received an M.Sc. in Robotics, Systems and Control from ETH Zurich in 2021
and was honored with the ETH Medal for an outstanding Master’s thesis.
Before that, I studied Computer Systems in Engineering at the University of Magdeburg, Germany and was a member of the RoboCup @Work team RobOTTO.
Education
Jul 2021 - Jun 2024
ETH Zurich, Switzerland
Ph.D. at the Computer Vision Lab with Prof. Luc Van Gool
Topic: Domain-Robust Network Architectures and Training Strategies for Visual Scene Understanding
ETH Medal for an outstanding PhD thesis
Topic: Domain-Robust Network Architectures and Training Strategies for Visual Scene Understanding
ETH Medal for an outstanding PhD thesis
Sep 2019 - Jun 2021
ETH Zurich, Switzerland
M.Sc. in Robotics, Systems and Control
ETH Medal for an outstanding Master thesis
ETH Medal for an outstanding Master thesis
Sep 2017 - Dec 2017
University of British Columbia Vancouver, Canada
Semester Abroad
Oct 2015 - Jan 2019
Otto von Guericke University Magdeburg, Germany
B.Sc. in Computer Systems in Engineering
Best Graduate at the Computer Science Department 2018/19
Best Graduate at the Computer Science Department 2018/19
Experience
Aug 2024 - Present
Google Zurich, Switzerland
Research Scientist
Apr 2023 - Nov 2023
Google Zurich, Switzerland
Student Researcher, Vision-Language Models
Feb 2019 - Jul 2019
Bosch Center for Artificial Intelligence Renningen, Germany
PreMaster Program, Explainable Artificial Intelligence
Oct 2018 - Dec 2018
Bosch Center for Artificial Intelligence Renningen, Germany
Research Internship, Environment Representations for Deep Learning
Teaching
Feb 2021 - Aug 2022
ETH Zurich, Deep Learning for Autonomous Driving, Teaching Assistant
Supervision of the course project on multi-task learning
Publications
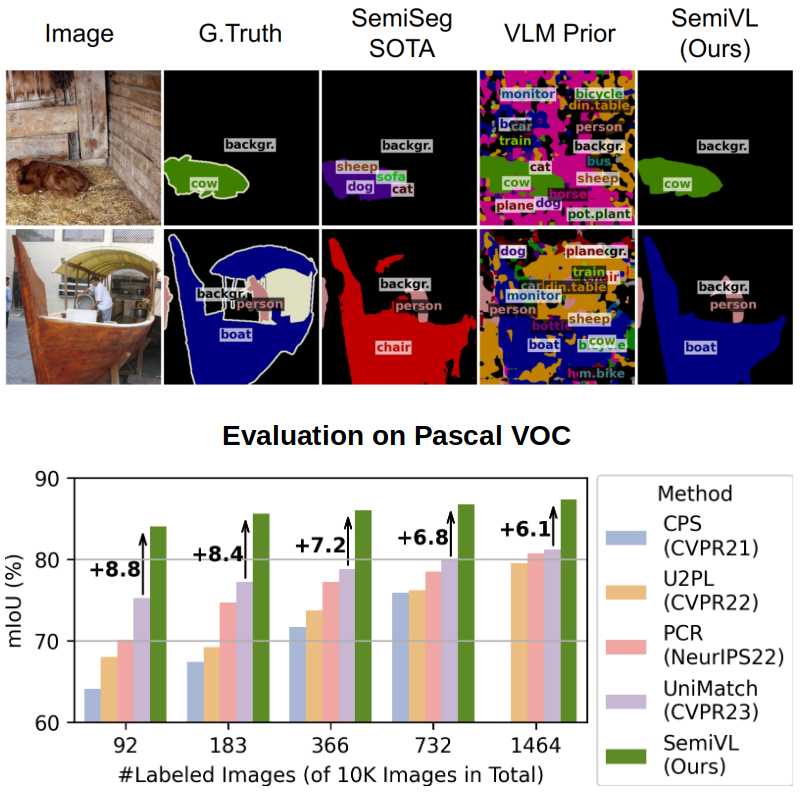
SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
European Conference on Computer Vision (ECCV), 2024
In semi-supervised semantic segmentation, a model is trained with a limited number of labeled images
to reduce the high annotation effort. While previous
methods are able to learn good segmentation boundaries, they are prone to confuse classes with similar
visual appearance due to the limited supervision. On the other hand, vision-language models (VLMs) are
able to learn diverse semantic knowledge from image-caption datasets but produce noisy segmentation due
to the image-level training. In SemiVL, we propose to integrate rich priors from VLM pre-training into
semi-supervised semantic segmentation to learn better semantic decision boundaries. To adapt the VLM
from global to local reasoning, we introduce a spatial fine-tuning strategy for label-efficient
learning. Further, we design a language-guided decoder to jointly reason over vision and language.
Finally, we propose to handle inherent ambiguities in class labels by providing the model with class
definitions in text format.
SemiVL achieves major gains over previous semi-supervised methods.

DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic
Control
European Conference on Computer Vision (ECCV), 2024
Latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate
creative content. However, are they usable as large-scale data generators, e.g.,
to improve tasks in the perception stack, like semantic segmentation? We investigate this question in
the context of autonomous driving, and answer it with a resounding "yes".
Our DGInStyle framework learns segmentation-conditioned image generation from synthetic
data while preserving the original diverse style prior of LDMs. Using DGInStyle, we
generate a diverse dataset of street scenes, train a semantic segmentation model on it,
and evaluate the model on multiple popular autonomous driving datasets.
DGInStyle improves the state of the art for domain-robust semantic segmentation by +2.5 mIoU.
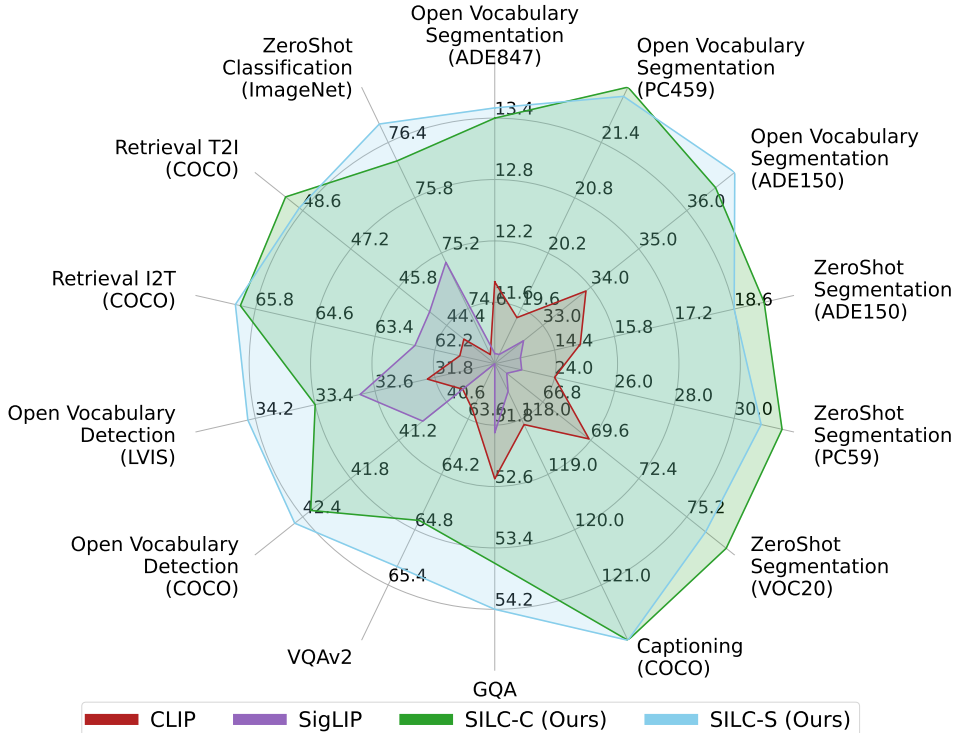
SILC: Improving Vision Language Pretraining with Self-Distillation
European Conference on Computer Vision (ECCV), 2024
Image-Text pretraining on web-scale image caption dataset has become the default recipe for open
vocabulary learning thanks to the success of CLIP and its variants. However,
the contrastive objective only focuses on image-text alignment and does not incentivise image feature
learning for dense prediction tasks. In this work, we propose the simple
addition of local-to-global correspondence learning by self-distillation as an additional objective for
contrastive pre-training to propose SILC. Our model SILC sets a new state of the art for zero-shot
classification, few shot classification, image and text
retrieval, zero-shot segmentation, and open vocabulary segmentation.
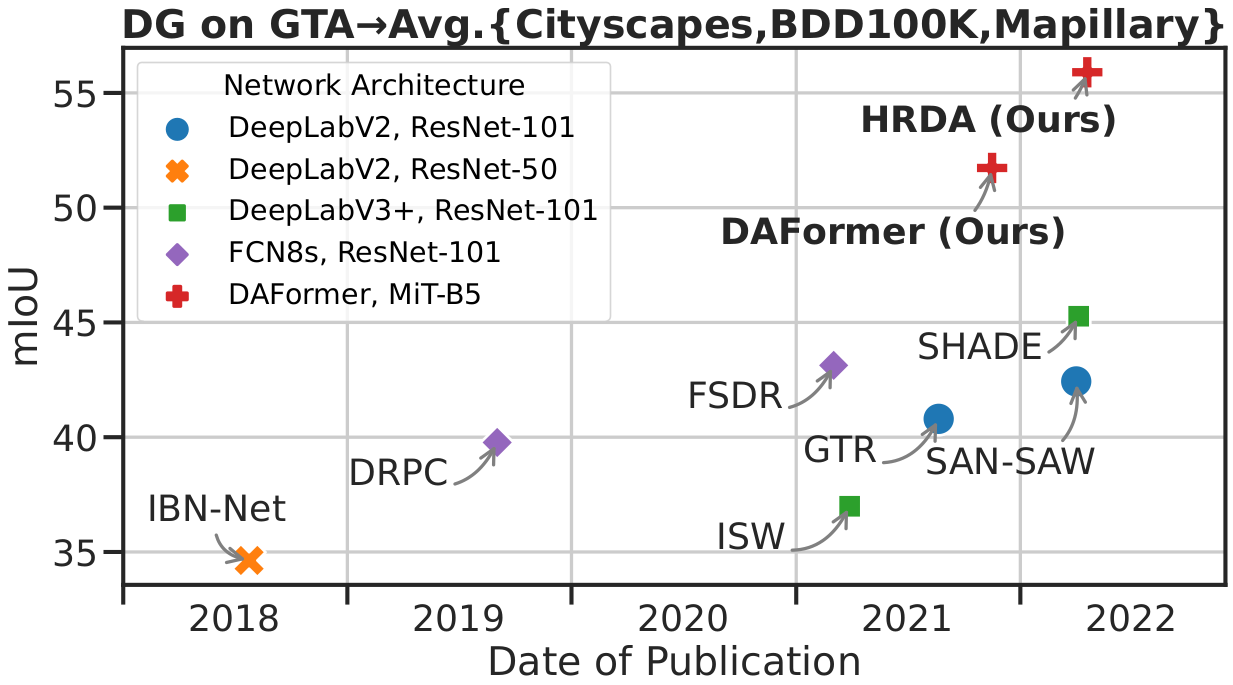
Domain Adaptive and Generalizable Network Architectures and Training Strategies for Semantic Image
Segmentation
Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2023
In this paper, we extend our DAFormer (CVPR22) and HRDA (ECCV22) beyond synthetic-to-real domain
adaptation to facilitate a more comprehensive view on domain robustness. In particular, we additionally
show the capabilities of both for day-to-night and clear-to-adverse-weather domain adaptation. Further,
we extend DAFormer and HRDA to domain generalization, enabling inference on unseen domains during test
time. DAFormer and HRDA significantly improve the state-of-the-art domain adaptation and generalization
performance by more than 10 mIoU on 5 different benchmarks.

EDAPS: Enhanced Domain-Adaptive Panoptic Segmentation
International Conference on Computer Vision (ICCV), 2023
In this work, we study domain adaptation for panoptic segmentation, which combines semantic and instance
segmentation. As panoptic segmentation has been largely overlooked by the domain adaptation community,
we revisit well-performing domain adaptation strategies from other fields, adapt them to panoptic
segmentation, and show that they can effectively enhance panoptic domain adaptation. Further, we study
the panoptic network design and propose a novel architecture (EDAPS) designed explicitly for
domain-adaptive panoptic segmentation. EDAPS significantly improves the state-of-the-art performance for
panoptic segmentation UDA by a large margin of 20% on SYNTHIA-to-Cityscapes and even 72% on
SYNTHIA-to-Mapillary Vistas.
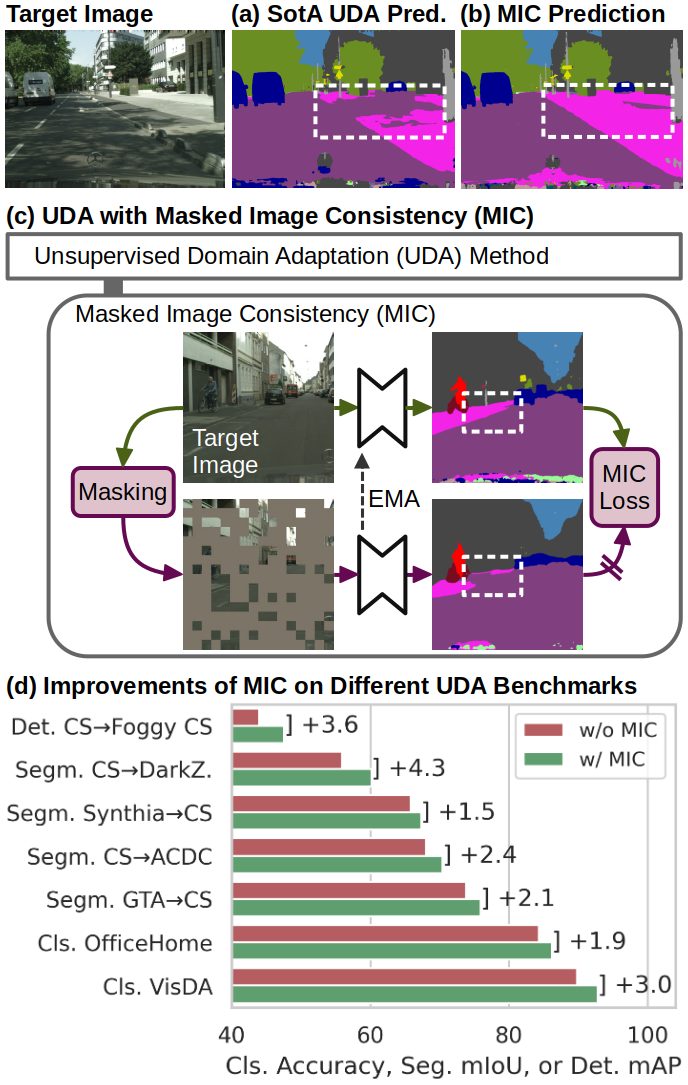
MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation
Conference on Computer Vision and Pattern Recognition (CVPR), 2023
In unsupervised domain adaptation (UDA), a model trained on source data (e.g. synthetic) is adapted to
target data (e.g. real-world) without access to target annotation. Most previous UDA methods struggle
with classes that have a similar visual appearance on the target domain as no ground truth is available
to learn the slight appearance differences. To address this problem, we propose a Masked Image
Consistency (MIC) module to enhance UDA by learning spatial context relations of the target domain as
additional clues for robust visual recognition. MIC enforces the consistency between predictions of
masked target images, where random patches are withheld, and pseudo-labels that are generated based on
the complete image by an exponential moving average teacher. To minimize the consistency loss, the
network has to learn to infer the predictions of the masked regions from their context. Due to its
simple and universal concept, MIC can be integrated into various UDA methods across different visual
recognition tasks such as image classification, semantic segmentation, and object detection. MIC
significantly improves the state-of-the-art performance across the different recognition tasks for
synthetic-to-real, day-to-nighttime, and clear-to-adverse-weather UDA. For instance, MIC achieves an
unprecedented UDA performance of 75.9 mIoU and 92.8% on GTA→Cityscapes and VisDA-2017, respectively,
which corresponds to an improvement of +2.1 and +3.0 percent points over the previous state of the art.
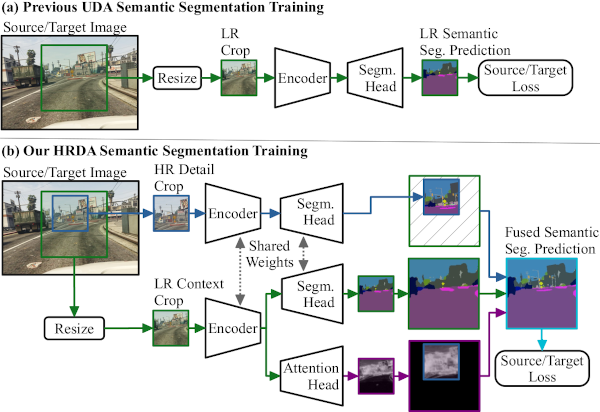
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
European Conference on Computer Vision (ECCV), 2022
Unsupervised domain adaptation (UDA) aims to adapt a model trained on synthetic data to real-world data
without requiring expensive annotations of real-world images. As UDA methods for semantic segmentation
are usually GPU memory intensive, most previous methods operate only on downscaled images. We question
this design as low-resolution predictions often fail to preserve fine details. The alternative of
training with random crops of high-resolution images alleviates this problem but falls short in
capturing long-range, domain-robust context information.
Therefore, we propose HRDA, a multi-resolution training approach for UDA, that combines the strengths of
small high-resolution crops to preserve fine segmentation details and large low-resolution crops to
capture long-range context dependencies with a learned scale attention, while maintaining a manageable
GPU memory footprint.
HRDA enables adapting small objects and preserving fine segmentation details. It significantly improves
the state-of-the-art performance by 5.5 mIoU for GTA→Cityscapes and by 4.9 mIoU for Synthia→Cityscapes,
resulting in an unprecedented performance of 73.8 and 65.8 mIoU, respectively.
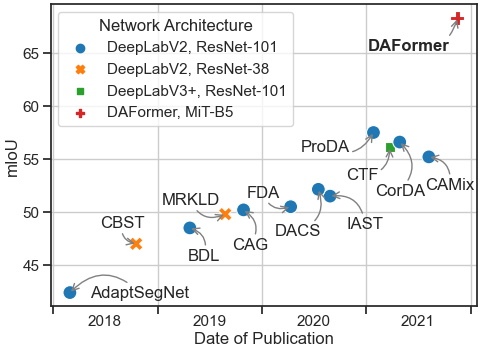
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic
Segmentation
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
As acquiring pixel-wise annotations of real-world images for semantic segmentation is a costly process,
a model can instead be trained with more accessible synthetic data and adapted to real images without
requiring their annotations. This process is studied in Unsupervised Domain Adaptation (UDA). In this
work, we particularly study the influence of the network architecture on UDA performance and propose
DAFormer, a Transformer network architecture tailored for UDA. It is enabled by three simple but crucial
training strategies to stabilize the training and to avoid overfitting the source domain. DAFormer
significantly improves the state-of-the-art performance by 10.8 mIoU for GTA→Cityscapes and by 5.4 mIoU
for Synthia→Cityscapes.
Improving Semi-Supervised and Domain-Adaptive Semantic Segmentation with Self-Supervised Depth
Estimation
International Journal of Computer Vision (IJCV), 2023
We extend our CVPR21 paper "Three Ways to Improve Semantic Segmentation with Self-Supervised Depth
Estimation" (see below) to semi-supervised domain adaptation featuring Cross-Domain DepthMix and
Matching Geometry Sampling to align synthetic and real data.
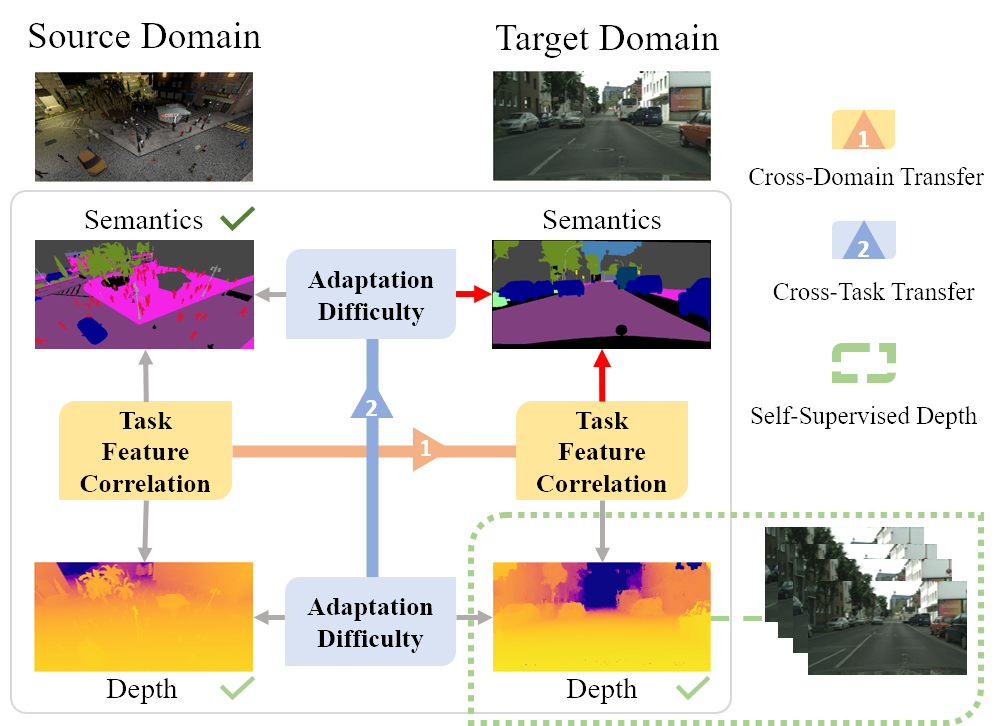
Domain Adaptive Semantic Segmentation with Self-Supervised Depth Estimation
International Conference on Computer Vision (ICCV), 2021
Domain adaptation for semantic segmentation aims to improve the model performance in the presence of a
distribution shift between source and target domain. In this work, we leverage the guidance from
self-supervised depth estimation, available on both domains, to bridge the domain gap. On the one hand,
we propose to explicitly learn the task feature correlation to strengthen the target semantic
predictions with the help of target depth estimation. On the other hand, we use the depth prediction
discrepancy from source and target depth decoders to approximate the pixel-wise adaptation difficulty.
The adaptation difficulty, inferred from depth, is then used to refine the target semantic segmentation
pseudo-labels.
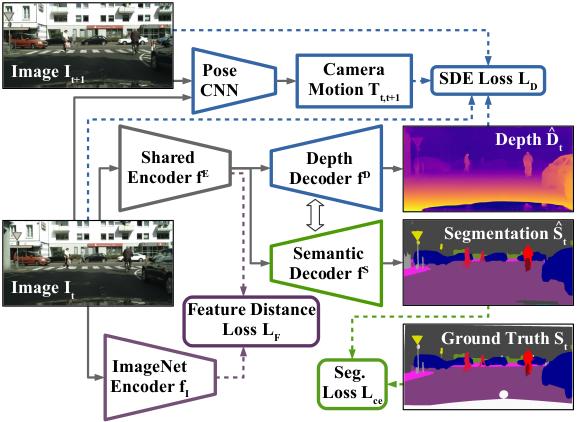
Three Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
We developed a method for improving semantic segmentation based on knowledge learned by self-supervised
monocular depth estimation from unlabelled image sequences. In particular, (1) we transferred knowledge
from features learned during self-supervised depth estimation to semantic segmentation, (2) we
implemented a strong data augmentation by blending images and labels using the structure of the scene,
and (3) we utilized the depth feature diversity as well as the level of difficulty of learning depth in
a student-teacher framework to select the most useful samples to be annotated for semantic segmentation.
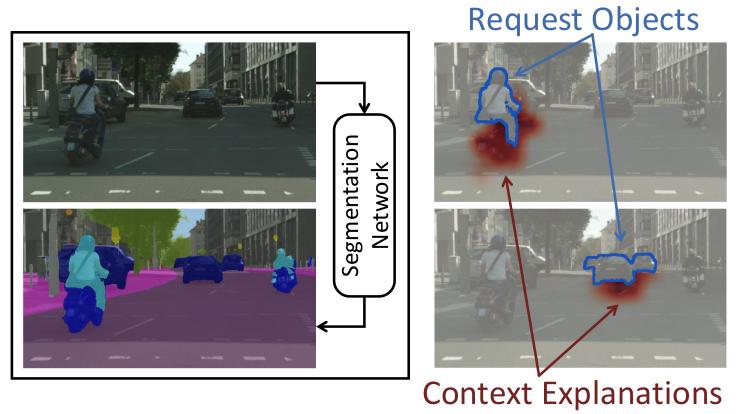
Grid Saliency for Context Explanations of Semantic Segmentation
Advances in Neural Information Processing Systems (NeurIPS), 2019 (Poster Presentation)
We extended saliency maps from classification to dense predictions to allow visual inspection of
semantic segmentation convolutional neural networks. We investigated the effectiveness of the proposed
Grid Saliency on a synthetic dataset with an artificially induced bias between objects and their context
as well as on real-world datasets. Our results show that Grid Saliency can be successfully used to
provide easily interpretable context explanations and, moreover, can be employed for detecting and
localizing contextual biases present in the data.
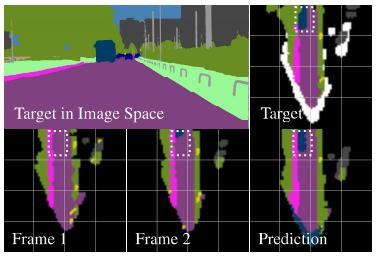
Short-Term Prediction and Multi-Camera Fusion on Semantic Grids
International Conference on Computer Vision (ICCV) Workshop CVRSUAD, 2019 (Poster Presentation)
We developed a self-supervised temporal prediction and multi-camera fusion system based on agent-centric
semantic maps. Semantic information from multiple cameras is integrated over multiple frames in a
unified semantic bird’s eye view environment representation.
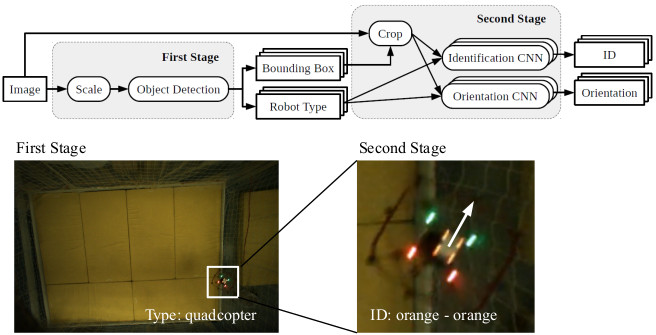
A Robot Localization Framework Using CNNs for Object Detection and Pose Estimation
IEEE Symposium Series on Computational Intelligence (SSCI), 2018 (Oral Presentation)
We designed and evaluated an external, camera-based localization and identification system for swarm
robots using convolutional neural networks. For a convenient system setup, we developed a low-effort
training data acquisition and synthetization process.
Projects

RoboCup Major @work
In the RoboCup @work team "RobOTTO", I helped to build an autonomous mobile robot for the transport of
work items in factories. From 2015 until 2018, I was responsible for the development of the state
machine, world model, task planner, and object recognition. In 2017, we achieved the 2nd place at the
World Cup.

RoboCup Junior Rescue-B
For the RoboCup Junior league Rescue-B (now Rescue Maze), we built and programmed a robot from scratch
to autonomously search for heat sources in a maze, which simulate victims in a building in danger of
collapsing. In 2013 and 2014, we achieved the 1st place at the World Cup competitions.

Spectral-Explorer
For the "Jugend forscht" German high school research competition, we developed a cost-effective optical
spectrometer for schools, which is more than 90% cheaper than regular devices. At the federal stage, we
received the award for non-destructive testing. After the competition, I scaled the prototype to small
batch production and equipped about 30 schools with the spectrometer.
Awards
Jan 2025
ETH Medal for Outstanding Doctoral Theses
Awarded to the best 8% PhD theses at ETH Zurich
Jun 2022
ETH Medal for Outstanding Master Theses
Awarded to the best 2.5% Master theses at ETH Zurich
Sep 2019 - Feb 2021
ETH Excellence Scholarship and Opportunity Program
Full, merit-based scholarship awarded to 0.5% of all master students at ETH Zurich
Jan 2016 - Jun 2021
Scholarship of the German Academic Scholarship Foundation
Merit-based scholarship awarded to 0.5% of all German students
Sep 2019 - Sep 2020
German Academic Exchange Scholarship (DAAD)
Merit-based scholarship awarded to German graduate students
Nov 2019
Graduation Awards of the University of Magdeburg
Best Graduate at the Computer Science Department 2018/19
Student Research Award for the Bachelor Thesis
Student Research Award for the Bachelor Thesis
Jul 2017
RoboCup, Major League @Work
2nd Place at the World Cup
May 2015
"Jugend forscht" German High School Research Competition
Award for Non-Destructive Testing
Jul 2014 & Jun 2013
RoboCup, Junior League Rescue-B
1st Place at the World Cup